Get ideas for new fuzz targets
In this user guide we highlight various ideas on how to use Fuzz Introspector to extract ideas for new targets. We will show a set of heuristics that each give some indication of why it’s relevant to use when searching for new fuzz targets. The relevance of each heuristic depends on each project, and we’re trying to list as many as possible so this can be used as a reference on how to apply Fuzz Introspector on your project.
Find functions that have an accumulated large code complexity
These are relevant because they reach a lot of logic.
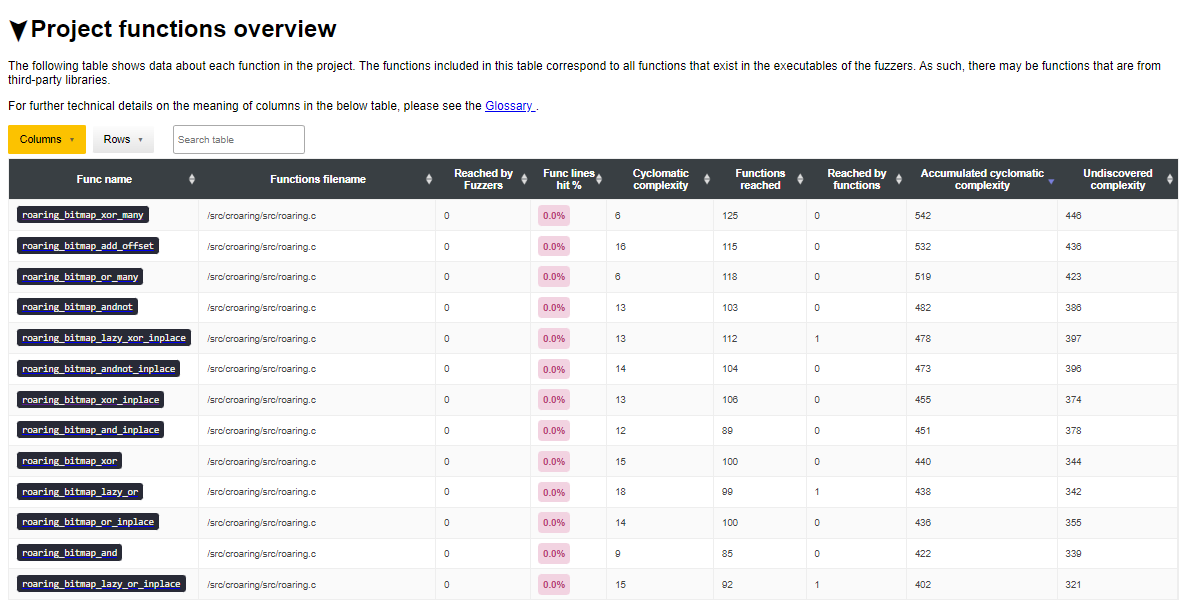
We will croaring as an example of this way to extract new targets. Consider
the following Project functions overview table in the OSS-Fuzz report:
https://storage.googleapis.com/oss-fuzz-introspector/croaring/inspector-report/20230115/fuzz_report.html#Project-functions-overview
In order to find the most complex targets in the project, we will sort the
table by Accumulated cyclomatic complexity, and we get the following result:
Find functions that have large undiscovered complexity
These may happen if they call into code that is already covered by other code, which is indeed reached by the fuzzer.
We use https://storage.googleapis.com/oss-fuzz-introspector/htslib/inspector-report/20230117/fuzz_report.html#Project-functions-overview as a reference.
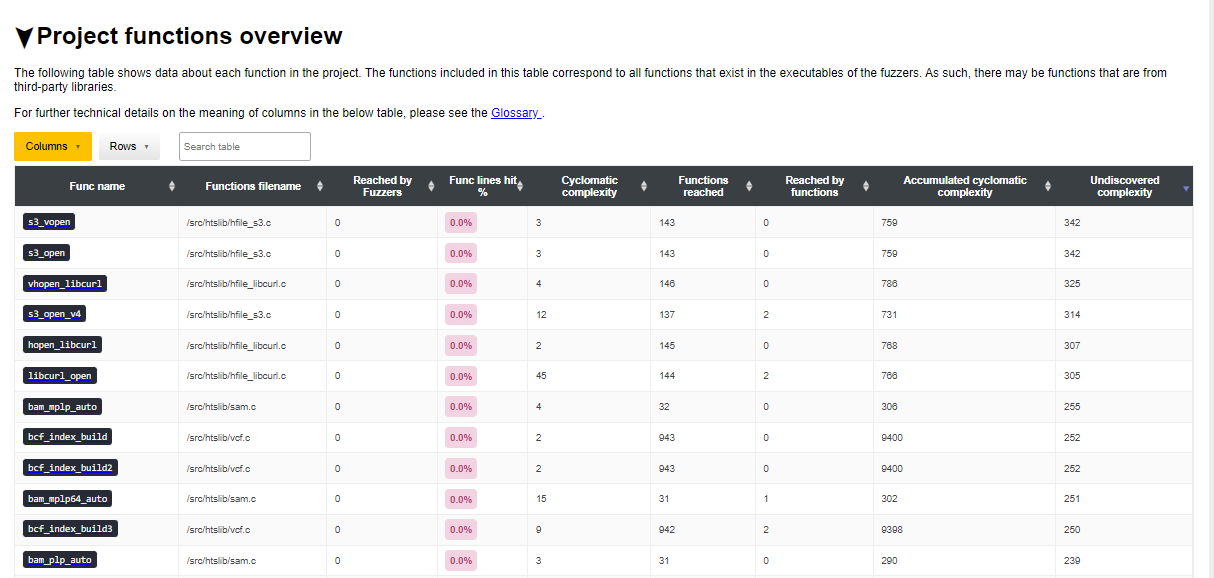
We sort the table by the rightmost column Undiscovered complexity. This
column gives us the reachable complexity by the given function discounting
the complexity that is reached by fuzzers. For example, assume function F1
reaches functions {F2, F3, F4} and Fuzzer X reaches functions {F4}, then the
undiscovered complexity of F1 is the sum of {complexity(F2), complexity(F3)}.
The rightmost column sorts by reachability, which is statically extracted.
We can confirm that none of the functions have any code coverage as well,
which is indicated by the Func lines hit% column.
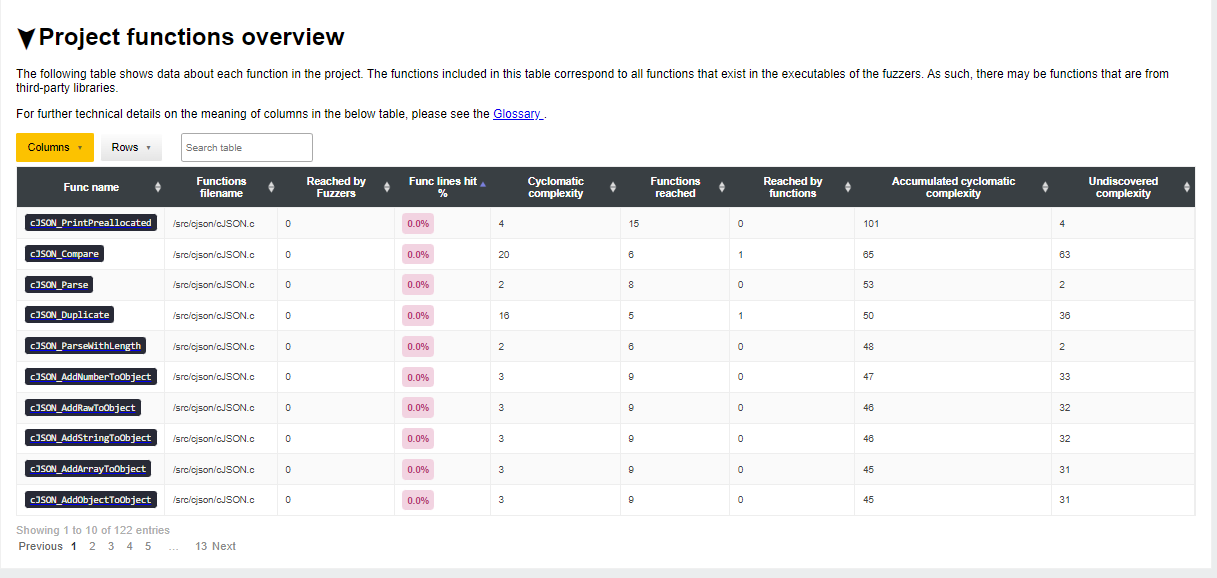
Find large functions with low code coverage
In order to find the largest functions with low code coverage we will use the
Project functions overview table and sort two of the columns:
First, sort by
Accumulated cyclomatic complexitySecond, sort by
Func lines hit%
This will give us the functions sorted by those with the most accumulated complexity and have the smallest amount of code coverage. These are interesting functions as they show the most complex functions in the code that are missing code execution by the fuzzers.
An example is the cjson project on OSS-Fuzz. The Project functions overview
table is available here: https://storage.googleapis.com/oss-fuzz-introspector/cjson/inspector-report/20230117/fuzz_report.html#Project-functions-overview and by sorting following the steps above we get:
Find functions with fuzzer-friendly names
A heuristic that is easy to use and can often be useful if you’re unfamiliar
with a given codebase is to search for functions with names that are
often fuzzer-relevant. Function names can often be a heuristic for the logic of
the function, and we often want to fuzz routines related to data handling.
Examples of interesting names to search for include parse, serialize and
decode.
libpcap example: In the following report of the libpcap project
https://storage.googleapis.com/oss-fuzz-introspector/libpcap/inspector-report/20230117/fuzz_report.html#Project-functions-overview we can search for parse
in the Project functions overview table. The result we get is:
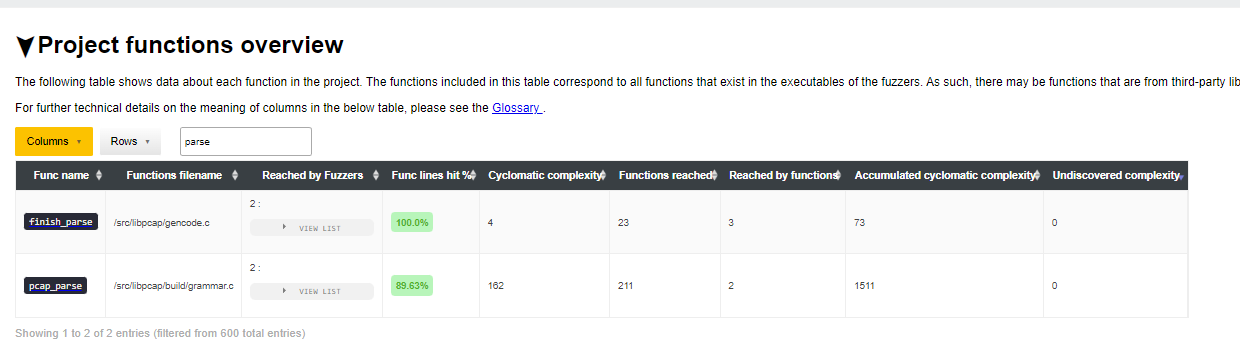
We find a function with relevant naming and can also observe this function has a reasonable large accumulated complexity. The function is already fuzzed and has a high amount of code coverage (88%), so there is not much more work to be done here.
pcapplusplus example: In the following report of the pcapplusplus project:
https://storage.googleapis.com/oss-fuzz-introspector/pcapplusplus/inspector-report/20230117/fuzz_report.html#Project-functions-overview
we can search for the “parse” keyword in the Project functions overview
and then also sort based on Undiscovered complexity to show us the most
promising functions of the parse functions. We get:
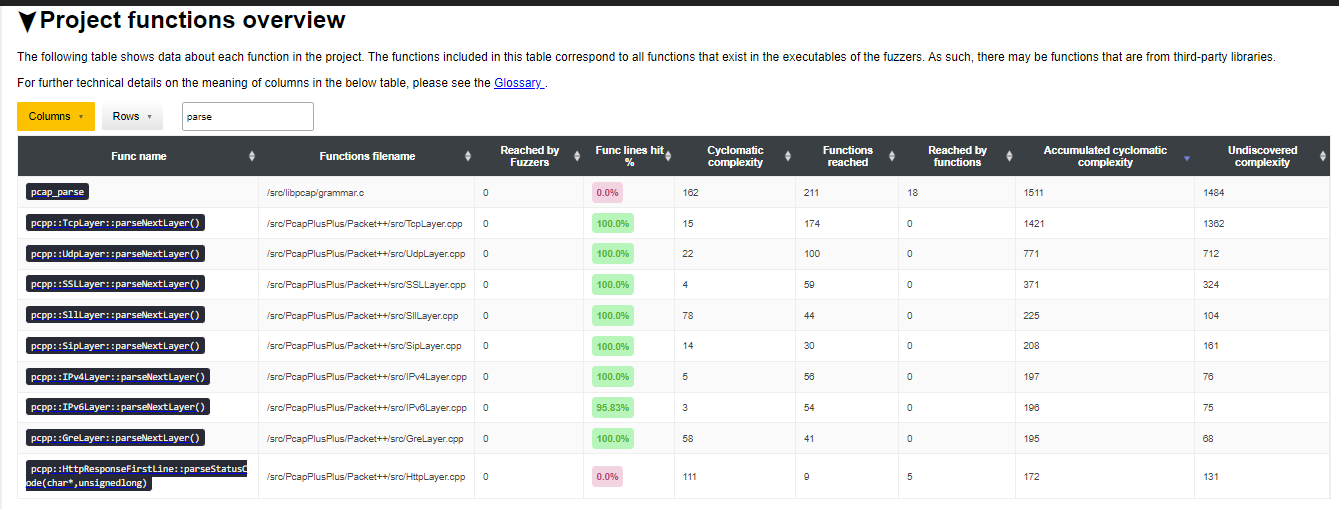
From the filename, we can see the top function is actually in a third party
dependency library, libpcap. The majority of the remaining parse functions
look to have good coverage.
We can also search for read in the project functions overview, which gives
us:
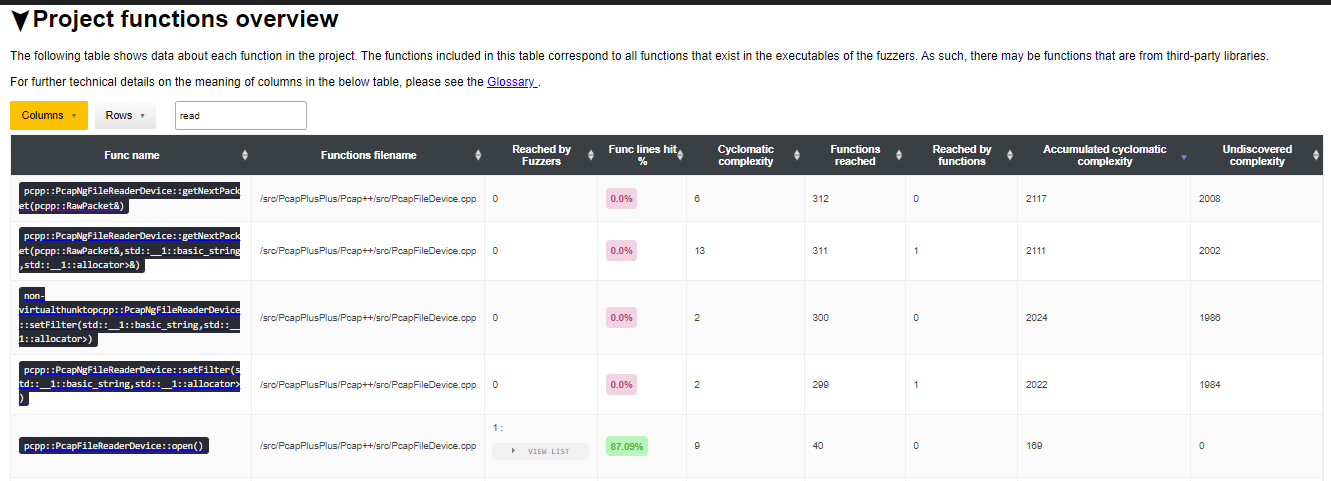
In the case of PcapPlusPlus we see in particular the read query gave samples
of interesting fuzz targets, namely functions that have 0 coverage, 0
reachability and fairly high accumulated complexity (~2000). These are all
good candidates for fuzz targets.
Find the most complex function in the target code
Note
Why is finding the most complex function useful?
We often aim to develop our fuzzers to analyse as much code as possible. This is why identifying the most complex functions in our code, or, even better to rank all functions based on the complexity they exhibit, since it guides us towards important functions to fuzz.
The reason we want the fuzzers to analyse as much code as possible is that code of higher complexity often exhibits more bugs in comparison to code of lower complexity. Furthermore, the more code we analyse of our software package also gives us higher assurance our code is safe.
Finding the most complex function.
# Run introspector
python3 ./infra/helper.py introspector libdwarf --seconds=5
# Start webserver
python3 -m http.server 8008 \
--directory ./build/out/libdwarf/introspector-report/inspector/
Following the above commands navigate to
http://localhost:8008/fuzz_report.html in your browser and the HTML report
will be accessible. Navigate to the Project functions overview table and
sort by the Accumulated cyclomatic complexity column in a descending
ordering.
This sorting will present functions sorted by total complexity, where total complexity is the sum of cyclomatic complexity of all functions reached by a given function.
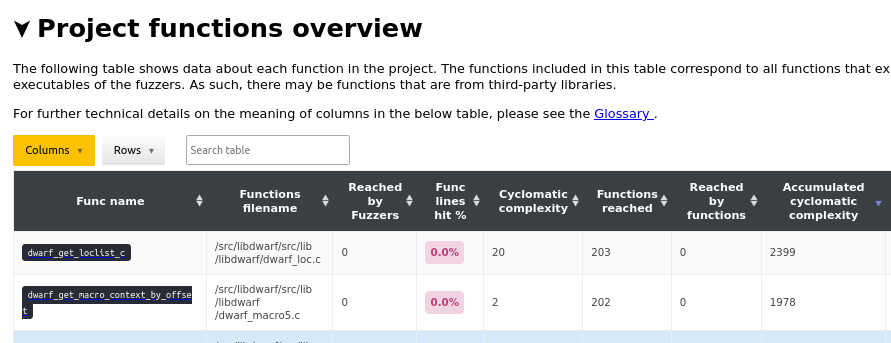
Find functions with no incoming reference
These are relevant because they are considered external functions.
Find functions that have large function call depth
These are relevant because they reach a lot of logic.